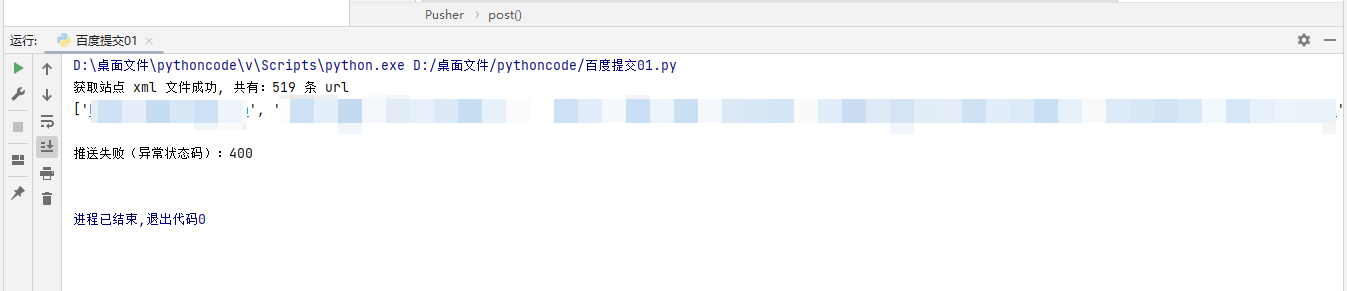
运行效果:
代码:
# -*- coding: UTF-8 -*-
import requests
import json
import re
class Pusher:
# 初始化参数
def __init__(self, site, token, sitemap_path):
self.site = site
self.token = token
self.sitemap_path = sitemap_path
# 批量提交 url
def post(self, urls):
post_url = f"http://data.zz.baidu.com/urls?site={self.site}&token={self.token}"
headers = {
'User-Agent': 'curl/7.12.1',
'Host': 'data.zz.baidu.com',
'Content-Type': 'text/plain',
'Content-Length': str(len(urls)),
}
response = requests.post(post_url, headers=headers, data=urls)
if response.status_code != 200:
print(f"推送失败(异常状态码):{response.status_code}")
print()
return None
response = response.text
response = json.loads(response)
if "error" in response:
print(f"推送失败(error)")
print(response)
print()
return None
if "success" not in response:
print(f"推送异常(百度已更改返回体格式)")
print(response)
print()
return None
print(f"已成功推送 {response['success']} 条 url")
print(f"当天剩余的可推送 url 条数 ---> {response['remain']}")
print()
return None
# 获取站点 sitemap.xml 文件内容, 解析 url
def get_url_from_sitemap(self):
url = f"{self.site}{self.sitemap_path}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"获取站点 xml 文件失败(异常状态码):{response.status_code}")
print()
exit(0)
sitemap_xml = response.text
urls = re.findall(r'<loc>(.+?)</loc>', sitemap_xml, re.S)
if urls is None or urls == [] or urls == "":
print(f"解析 url 失败(该站点不存在 sitemap.xml 或内容为空)")
print()
exit(0)
print(f"获取站点 xml 文件成功, 共有:{len(urls)} 条 url")
print(urls)
print()
return urls
# 入口
def main(self):
urls = self.get_url_from_sitemap()
body = ""
for url in urls:
body += f"{url}n"
self.post(body)
if __name__ == '__main__':
# 站点
site = "https://www.xxx.cn"
# 百度提交页面提供的 token
token = "0umWUJcYh0Hsyarf"
# 站点 sitemap uri
# sitemap_path = "/zh-cn/sitemap.xml"
sitemap_path = "/sitemap.xml"
pusher = Pusher(site, token, sitemap_path)
pusher.main()



